General¶
So, what is a Discovery?
Before you can translate a website, you need to extract all content from it using the Scan function. A Scan, however, writes to the database, which, as you know from our pricing model, will cost you money. In that sense, it would be risky to let loose an unlimited Scan on a website you’re not familiar with. To forego Content Extraction and limit the crawler’s actions to finding out about the structure and word count of a given web site, a more tentative approach is needed: a Discovery.
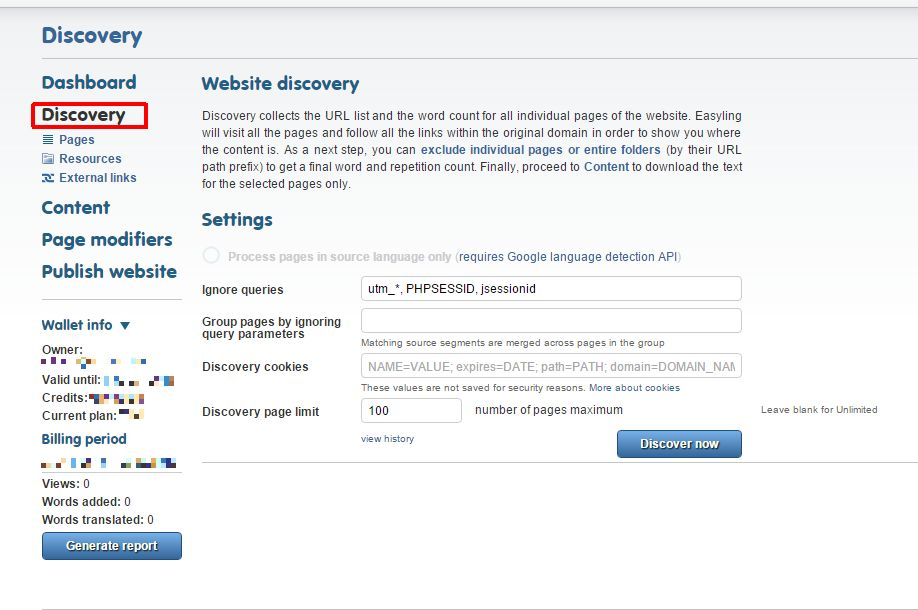
The process maps the structure of the site by scanning each page for link elements and trying to follow these links. The content of the website is not stored, only the URL address of the visited pages, together with their status info. Any page that is verified to exist is marked as Discovered, and the ones that returned an error message (most commonly redirection (HTTP301-302) and page not found (HTTP404)) are marked Unvisited in the page list. For more information on HTTP status codes, see here. Although this process doesn’t extract content, it provides a preliminary wordcount and a repetition rate as well. It has a cost of 1EUR per thousand pages.
IMPORTANT!
If you exclude pages during discovery, changing the rules only will not include them in the new discovery; you have to add them manually through the “Add pages” dialog.
Your primary choice is between limited and unlimited Discoveries.
A limited Discovery is the best way to “get to know” a website - if you set a reasonable safety number, such as the default 100, you can be sure the process will go overboard when it finds an enormous forum or a structurally complicated web-shop.
Based on what a limited Discovery tells you about a site, you can set prefix exclusion rules in the page list or cherry-pick unnecessary pages for exclusion.
Wordpress sites, for example, tend to create links such as “/?page=2332” for every page, and it is obvious from the get-go that there is no real content behind these links. A limited Discovery will inform you of their presence, so that you can exclude them at.
By increasing the page limit and running Discoveries in succession while adjusting your inclusion/exclusion rules, you can work your way through a site structure incrementally.
Of course, if you have a clear idea of the size of the site, you can always set up an unlimited Discovery, wait for it to finish and set up your exclusion rules afterwards.
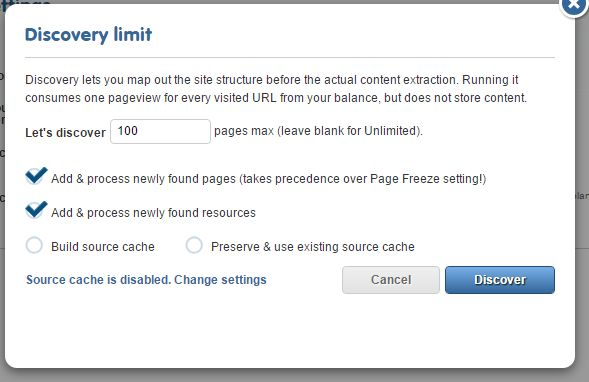
Once the discovery is ready, you will receive an e-mail notification and the statistics will show up on the Discovery page. Based on this you can give a rough estimation for the website translation cost - both in time and money.