Pages¶
The page list lets you keep track of the various URLs that are (or were) seen by the proxy. It can be accessed from both the Discovery and Content menus (See the note on the Add Pages dialog elow for one crucial difference).
Aside from the overview of and direct access to content on the individual pages, the page list also allows you to visit the various proxy preview domains, fine-tune inclusion/exclusion settings and check the translation progress of individual pages.
Side menu¶
The number of pages that are displayed is influenced by the various filters available in the left-side menu:
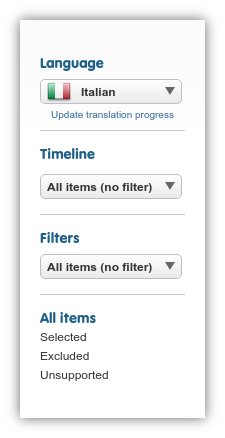
Language Selector¶
Though strictly speaking not a filter at all, the language selector influences the page list in important ways. Information in the translation progress bars will refer to the selected language, and both the List and Highlight Views will open for the selected target language. The same is true for the various types of Preview links.
Ensure that you have selected a target language to gain access to many powerful features in the page list. If you do not (or there is no target language on the project at all, in which case, the source language is selected), then neither the Workbench links, nor the Previews will be available, and most of the hover menu options will be greyed out:

Update Translation Progress link¶
Click here whenever you want to receive updated information about the current translation ratio in the page progress bars. Information will refer to the selected target language. Updates are automatically run every 24 hours. Note that the process can take from a few seconds to a few minutes of time to finish, depending on the amount of content to be aggregated.
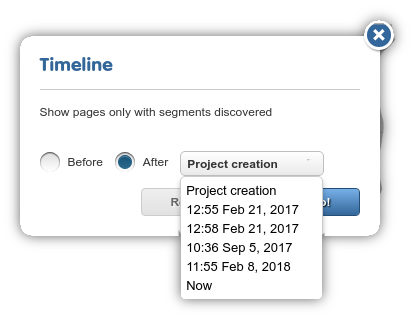
Timeline¶
Use the dropdown illustrated the screenshot below to filter for pages that registered new content (either via a content extraction crawl or automatic extraction in Preview) before or after a given recorded date. Set the value to “After Project creation” or click on Reset timeline to undo this filter.
Filters¶
This dropdown, though it may sound general, does a specific thing: lets you filter for pages that are in the selected state. The possible options are
- Visited (Scanned) only: filter for pages that are already Scanned (content extracted). These pages will show a status of “NEW” or a translation progress bar, indicating that they are in-progress.
- Unvisited only: filter for pages that are referenced on some other visited page and their URLs were added to the page list, but neither a word count, nor a content extraction crawl has had a chance to process them yet.
- Discovered only: filter for pages that were word counted before. Note that the “Discovered” note to the right of a page does not tell you the details of which crawl Discovered this page, so you can’t automatically assume that all Discovery statistics contain the word count from it.
- All items: disable this filter.
Exclusion State¶
A project can keep tabs on many distinct URLs. For example, query parameters, especially in combination tend to increase the number of URLs, potentially crowding the page list and resulting in much unnecessary scrolling. Use the exclusion filters at the bottom of the side menu (and in combination with the search field on top) to get a clear view of your currently selected or excluded set of URLs (see below for the details of exclusion/inclusion rules).
Note that you can use the search field to search for any part of a URL, not just the beginning.
Top Menu¶

The following features are available in the top menu:
- Export page list
- Add New Pages
- Mass Exclusion of URLs
- Include/Exclude
- Search
See below for the details of each feature.
Page list export¶
Clicking on this icon presents you with your current selection of pages in an easy to copy & paste format (autoselected).
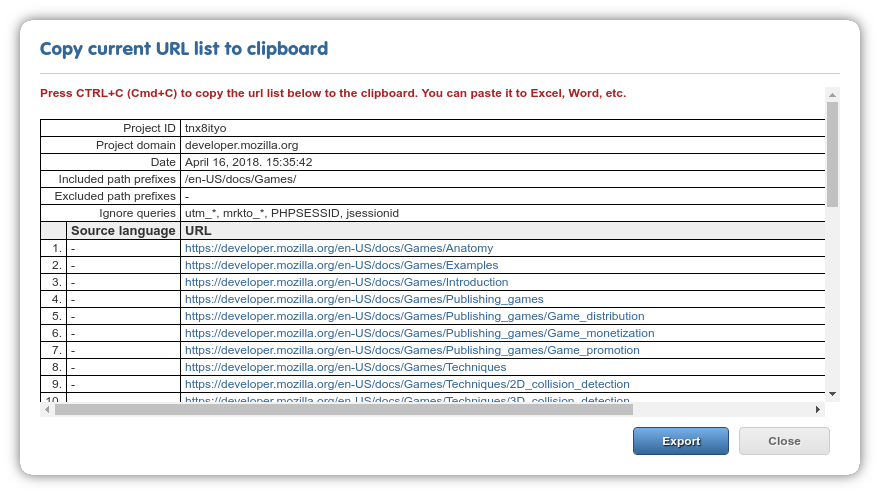
Above a certain reasonable threshold, the Dashboard will not render the whole page list in the dialog, and you will receive a message that the page list is too big. The option to export as XLS remains avaialble in both cases.
Add New Pages¶
The Add pages dialog is a powerful feature: it lets you start page-specific crawls. Use it to add new pages or refresh already extracted pages in a “surgical” fashion.
You might find yourself in a situation where a specific set of pages would benefit from a content extraction, but you don’t want to start a full crawl for this purpose alone. Perhaps you’d like to add a few images for localization (it is frequent that only a few of the images on a site require translation, so this use case tends to come up a lot).
The Add Pages lets you do all these things without the overhead of a full-blown crawl.
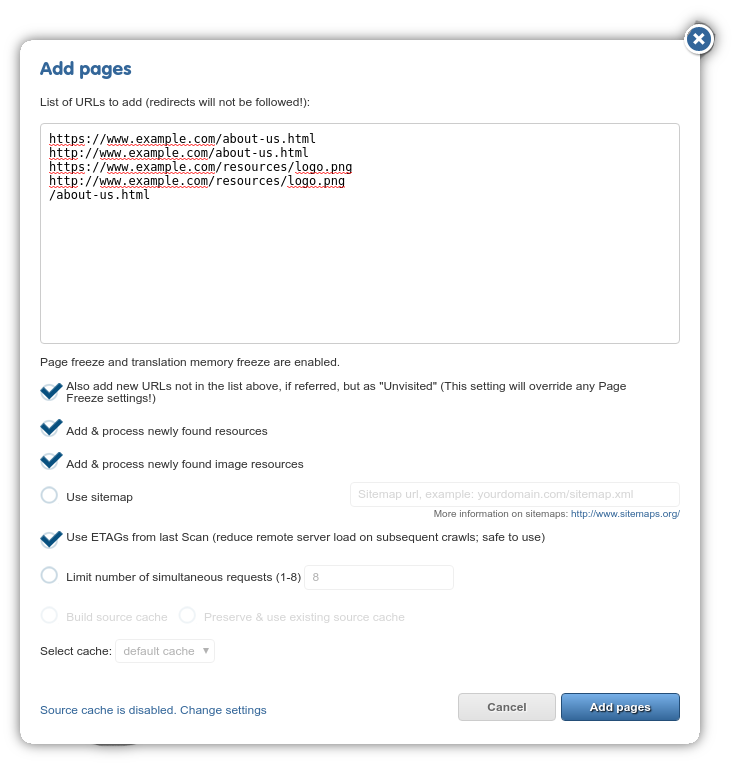
Note the examples in the screenshot: HTTPS URLs are added using fully qualified URLs. If you specify the pathname only, such as /about-us.html in the screenshot above, the proxy will default to requesting the page over HTTP. The same applies to any resource that is available via both HTTP and HTTPS: add both URLs to ensure that you have all possible versions of the resource.
Features that limit the crawl’s scope (e.g. page limit) are not present in this dialog as the list of URLs effectively tells the crawler where to go. Source cache-related settings are available, however, you have the option to add a sitemap link for the proxy to crawl.
IMPORTANT! There is an important difference between the Add Pages dialogs of the two page lists: If the Add Pages dialog is opened from Discovery > Pages, it will start a word count Discovery; opening it from the Content > Pages menu will result in a content extraction Scan!
Mass Exclusion¶
We mentioned previously that the proxy can exclude pages in two ways: by applying a prefix rule or by manual exclusion. But sometimes, a prefix-based approach is “too inclusive”. At the same time, exclusion of large numbers of URLs by hand is tedious. Click on this icon and copy & paste URLs in the opening dialog to apply manual exclusion to those URLs en-masse.
It pays to be careful, however: keep in mind that if you lose the list, your only option will be to re-include the pages is one-by-one manual action (unless, of course, you can re-generate the list of URLs via the page list filters).
In general, inclusion/exclusion rules are a better approach if your scope can be specified with them.
Inclusion/exclusion rules¶
Inclusion rules let you set the scope of translation, that is, the list of pages that the crawler is allowed to visit. Inclusions fall into two main categories, prefix and manual. We discuss the prefix-based rules in this subsection.
When you click on the “Sheet & Gear” icon, the top menu and the search bar is transformed into the inclusion / exclusion rule editor as shown in the screenshot below:
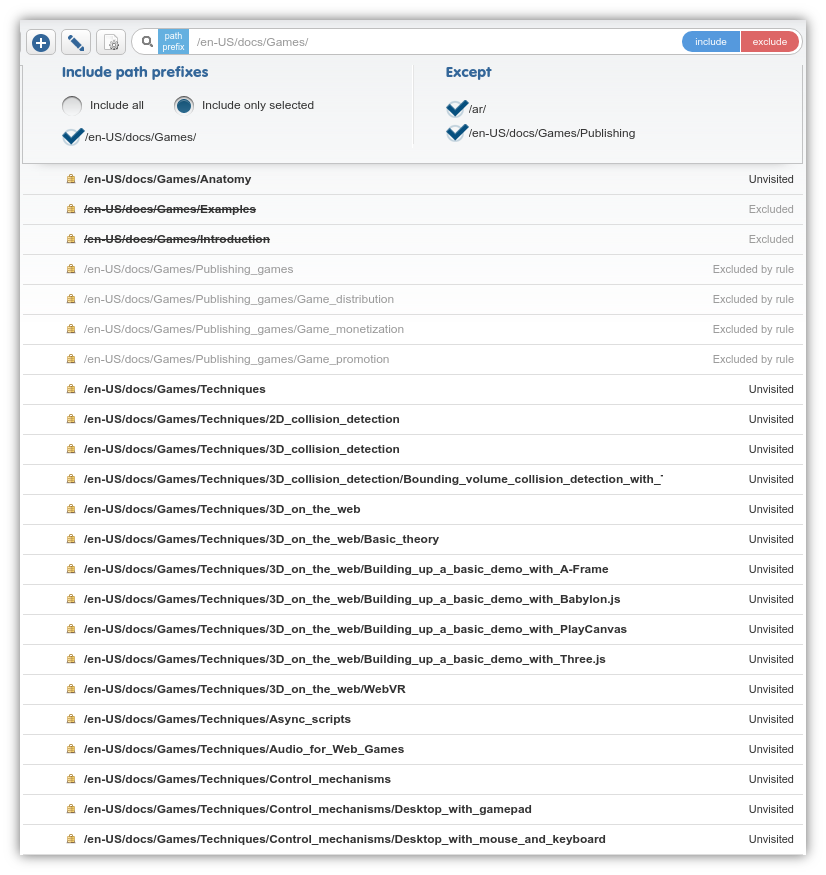
The Dashboard has a number of features that support inclusion/exclusion prefixes, such as auto-pretranslation or work packages. But the rules you specify here are special and powerful: they have influence over the entire project.
An excluded page will stay untranslated over any proxy domains (both Preview and Live), and excluded pages are ignored by the crawler.
Type or copy & paste an URL into the search field when the rule editor is active, and click on either “Include” or “Exclude” to add it to the appropriate column. If you add a fully-qualified URL via copy & paste, the scheme/domain part is automatically stripped.
Include path prefixes¶
A set of radio buttons in the inclusion column lets you toggle inclusion rules on your project.
Include All disables any inclusion limits on the project. No rule in the include column will be applied. but exceptions listed in the “Except” column on the right will be adhered to.
Include only selected enables inclusion-based limitations. E.g., if you have a single inclusion prefix /en/ in the left side list and enable “Include only selected”, the crawler will only process pages that can be found in the /en/ directory on the server (to put it more accurately, it will process only those URLS in which the pathname part matches the string /en/ from the beginning).
If you have multiple inclusion rules listed, you can selectively enable/disable any one of them using the checkboxes to the left of each rule. If you hover over a rule, a small delete icon will appear to the right, use this to remove a rule.
Unless you specify further inclusion rules and fine-tune your scope with exclusion rules, the proxy will ignore all pages outside of this directory.
Except¶
Exception rules don’t need to be enabled “generally” in the way that inclusion rules do: if you add an URL prefix as an exclusion and leave the checkbox to its left enabled, it will always be applied.
Rule Application¶
Whenever the proxy comes across a page in an affected context (crawling, serving, translating, etc.), it will evaluate it according to the rules you provide. This process is summarized in the flowchart below:
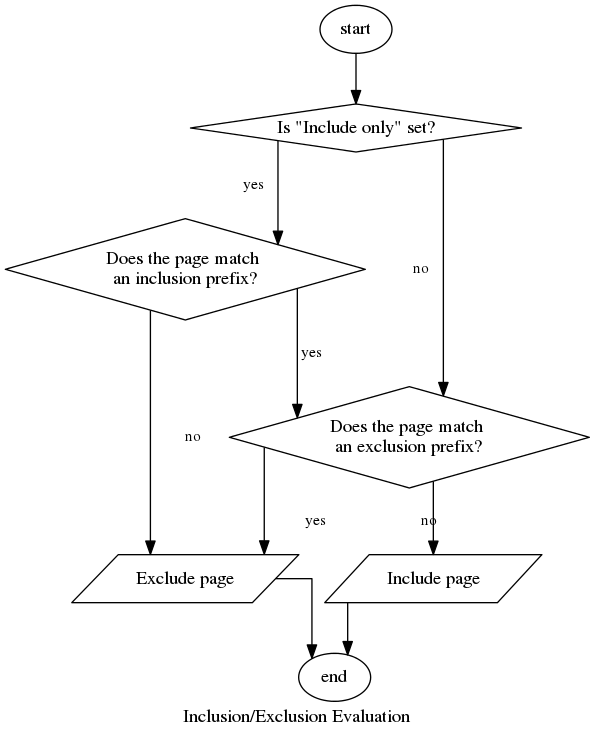
A few points of note concerning inclusion/exclusion rules:
- pathnames are first checked for inclusion, then exclusion.
- a pathname has to match only one from the set of enabled rules. Each such rule is applied to the path in sequence until a match is found or there are no more rules.
- the rules are strings and matched from the beginning of the pathname. The proxy does not analyze them in detail or produce complex internal representations.
- query parameters are supported (but be careful, you can’t really count on a query parameter to have a set position!).
- if a path falls outside of the scope of your inclusion rules or an exclusion rule applies to it, it will be greyed out in the page list and the text “Excluded by rule” will be visible next to it.
- Rule-excluded paths cannot be un-excluded directly or via the Mass exclusion dialog, and the hover menu button you can ordinarly use for the purpose will be missing. You need to edit your rules if they gobble a path that you want.
NOTE: If all pages are excluded on a project, crawls cannot be started, even if the currently active rules would allow for the inclusion of some, as-of-yet undiscovered page. In this case, crawls will exit after 0 pages visited. You have to ensure an entry point: that at least one of the known pages is in an included state. Otherwise, the crawler can’t set its foot in the door.
Though it may seem nonsensical to exclude every single URL on a project, we note this unusal case because it can come about from inadvertent use of inclusion rules.
Consider, for example, that if you set /en/ as the sole “Include only” rule on your project, but no page starting with /en/ is in the page list, then not a single valid entry point is provided to the crawler.
Page List¶
The page list contains all pages that the proxy has seen and collected previously, either via crawls or via user visits (to prevent the page list from being automatically extended in this latter fashion, enable “Page Freeze” in Advanced settings).
Parts of a page list entry¶

- HTTPS icon
- pathname
- hover menu
- translation state
The proxy handles HTTP and HTTPS pages separately on the assumption that content between the two can potentially differ. You will see a yellow padlock icon next to HTTPS pages. Click on the pathname of a page list item to visit the original page.
Translation State¶
There are a number of states that a page can be in throughout the lifetime of a project (we have already alluded to this fact above in connection with filtering options). The current state of a page is shown in the rightmost column of a page list item.
- Unvisited: indicated pages that were already seen in the source of another page, added to the list, but for one reason or another, not visited by a crawler. For example, if you run a Discovery with a page limit of 8 and allow it to collect new URLs at the same time, it will likely visit the landing page, “/”. The landing page is likely contain many references to various pages on the same domain. THe Discovery will exit after 8 pages, but also add the rest as “Unvisited”.
- Discovered: a page that was included in a word count previously is said to be Discovered. The content on it is accounted for in at least one of the word count statistics, but the translatable content has not been extracted for translation yet.
- NEW: the “new” in this part refers to the fact that the page is content extracted and in a “pristine” state: no entries on it have been translated yet. It is usual to find pages in “NEW” state right after the first content extraction crawl (when a project has all the content ready for translation, but no translations have been provided yet).
- Progress bar: will be shown when a non-zero percentage of the entries that the given page refers to have been translated. Note that due to automatic propagation, translating one entry can influence the progress bars of multiple pages). Hovering over the progress bar will show more specific numbers in the tooltip, but progress is also color-coded as follows (end value decimal places are omitted):
progress < 30%- redprogress < 60%- yellowprogress < 100%- greenprogress = 100%- blue
Last Seen Status Code¶
The proxy also provides information on the status code with which the individual pages last responded with.
Only the most important subset of status codes is reported. 301 Moved Permanently and 302 Found redirects are shown in green, 404 Not Found and 500 Internal Server Error status codes are displayed in red.
Refer to Google or the very thorough RFC 7231 for a detailed description of HTTP status codes.
Page deletion¶
A project, especially one with few inclusion/exclusion rules or one that uses URLs with many query parameters can over time accure many pages in the page list. Page deletion is not available on the Dashboard for reasons of content safety and simplicity at this time.
If you’d like to have some subset of the pages deleted from your project, feel free to contact support and we’ll help you with project cleanup. In the meantime, stay tuned until page deletion is introduced as a user feature.